Šířka pásma používaná v UMA do paměti je omezena, protože používá řadič s jednou pamětí. Hlavním motivem příchodu strojů NUMA je zvýšení dostupné šířky pásma paměti pomocí více paměťových řadičů.
Srovnávací graf
| Základ pro srovnání | UMA | NUMA |
|---|---|---|
| Základní | Používá řadič jediné paměti | Řadič více paměti |
| Typ použitých autobusů | Jeden, vícenásobný a příčný nosník. | Strom a hierarchie |
| Doba přístupu k paměti | Rovnat se | Změní se podle vzdálenosti mikroprocesoru. |
| Vhodné pro | Obecné použití a aplikace pro sdílení času | Real-time a časově kritické aplikace |
| Rychlost | Pomaleji | Rychlejší |
| Šířka pásma | Omezený | Více než UMA. |
Definice UMA
Systém UMA (Uniform Memory Access) je architektura sdílené paměti pro multiprocesory. V tomto modelu je používána jediná paměť, ke které mají přístup všechny procesory prezentující multiprocesorový systém pomocí propojovací sítě. Každý procesor má stejnou dobu přístupu do paměti (latence) a rychlost přístupu. To může používat jeden sběrnici, více sběrnice nebo přepínač příčky. Vzhledem k tomu, že poskytuje vyvážený přístup ke sdílené paměti, je také znám jako SMP (symetrický víceprocesorový) systém.
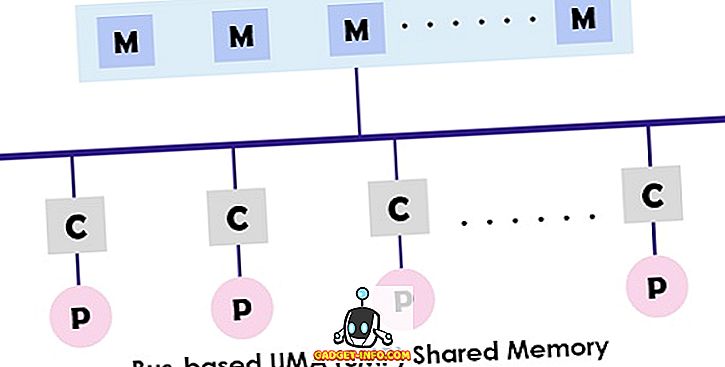
Typický design SMP je zobrazen nahoře, kde je každý procesor nejprve připojen k mezipaměti, poté je cache propojena se sběrnicí. Konečně je sběrnice připojena k paměti. Tato architektura UMA snižuje nárok na sběrnici prostřednictvím načtení instrukcí přímo z jednotlivé izolované mezipaměti. Rovněž poskytuje stejnou pravděpodobnost čtení a zápisu každému procesoru. Typickými příklady modelu UMA jsou servery Sun Starfire, server Compaq alfa a série HP v.
Definice NUMA
NUMA (Non-uniform Memory Access) je také multiprocesorový model, ve kterém je každý procesor připojen k vyhrazené paměti. Tyto malé části paměti se však spojí, aby vytvořily jeden adresní prostor. Hlavním bodem k zamyšlení je, že na rozdíl od UMA se čas přístupu paměti spoléhá na vzdálenost, ve které je procesor umístěn, což znamená změnu doby přístupu do paměti. Umožňuje přístup k libovolnému umístění paměti pomocí fyzické adresy.
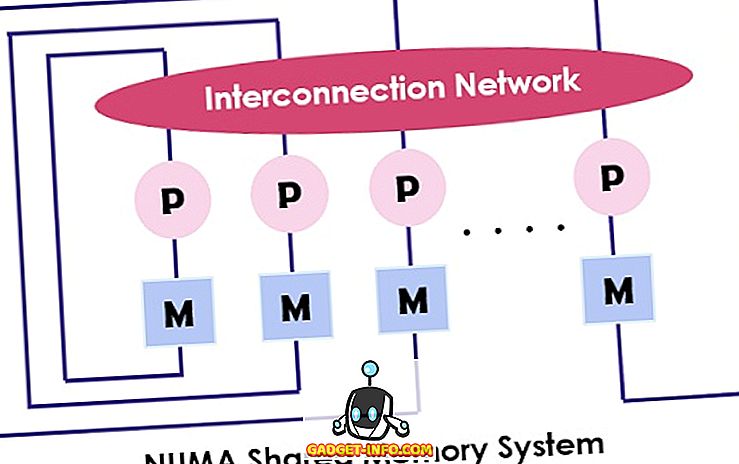
Jak bylo uvedeno výše, architektura NUMA je určena ke zvýšení dostupné šířky pásma paměti a pro kterou používá více paměťových řadičů. Kombinuje četná jádra strojů do „ uzlů “, kde každé jádro má řadič paměti. Pro přístup k lokální paměti v počítači NUMA jádro načte paměť spravovanou řadičem paměti svým uzlem. Při přístupu ke vzdálené paměti, kterou obsluhuje druhý řadič paměti, jádro odešle požadavek na paměť prostřednictvím propojovacích článků.
Architektura NUMA používá stromové a hierarchické sběrnicové sítě k propojení paměťových bloků a procesorů. BBN, TC-2000, SGI Origin 3000, Cray jsou některé z příkladů architektury NUMA.
Klíčové rozdíly mezi UMA a NUMA
- Model UMA (sdílená paměť) používá jeden nebo dva řadiče paměti. NUMA může mít k paměti přístup více paměťových řadičů.
- V architektuře UMA se používají jedno-, vícenásobné a příčné nosníky. NUMA naopak používá hierarchické a stromové typy sběrnic a síťového připojení.
- V UMA je doba přístupu do paměti pro každý procesor stejná, zatímco v NUMA se čas přístupu k paměti mění jako vzdálenost paměti od procesoru.
- Pro stroje UMA jsou vhodné aplikace pro všeobecné použití a sdílení času. Naproti tomu vhodná aplikace pro NUMA je v reálném čase a časově kritická.
- Paralelní systémy založené na UMA pracují pomaleji než systémy NUMA.
- Pokud jde o šířku pásma UMA, mají omezenou šířku pásma. Naopak, NUMA má šířku pásma větší než UMA.
Závěr
Architektura UMA poskytuje stejnou celkovou latenci procesorům přistupujícím k paměti. To není příliš užitečné, pokud je místní přístup k paměti, protože latence by byla jednotná. Na druhou stranu, v NUMA měl každý procesor svou vyhrazenou paměť, která eliminuje latenci při přístupu k místní paměti. Latence se mění jako vzdálenost mezi změnou procesoru a paměti (tj. Nerovnoměrná). Nicméně, NUMA zlepšila výkon ve srovnání s UMA architekturou.