



Obě metody třídění, rychlé třídění a slučování jsou postaveny na metodě dělení a dobývání, ve které je sada prvků rozdělena a poté kombinována po přeskupení. Rychlé řazení obvykle vyžaduje více porovnání než třídění sloučení pro třídění velké množiny prvků.
Srovnávací graf
| Základ pro srovnání | Rychlé řazení | Sloučit třídění |
|---|---|---|
| Rozdělení prvků v poli | Rozdělení seznamu prvků není nutně rozděleno na polovinu. | Pole je vždy rozděleno na polovinu (n / 2). |
| Nejhorší případová složitost | O (n2) | O (n log n) |
| Dobře funguje | Menší pole | Pracuje jemně v každém typu pole. |
| Rychlost | Rychlejší než jiné třídicí algoritmy pro malý soubor dat. | Konzistentní rychlost ve všech typech datových sad. |
| Další požadavky na úložný prostor | Méně | Více |
| Účinnost | Nevhodné pro větší pole. | Efektivnější. |
| Metoda třídění | Vnitřní | Externí |
Definice rychlého řazení
Rychlé třídění je pervasively používal třídící algoritmus jak to je rychlé pro krátká pole. Sada prvků je rozdělena na části opakovaně, dokud ji nelze dále rozdělit. Rychlé třídění je také známé jako výměna oddílů . Pro rozdělení prvků používá klíčový prvek (známý jako pivot). Jeden oddíl obsahuje prvky, které jsou menší než klíčový prvek. Jiný oddíl obsahuje ty prvky, které jsou větší než klíčový prvek. Prvky jsou tříděny rekurzivně.
Předpokládejme, že A je pole A [1], A [2], A [3], …… .., A [n] n čísla, které musí být tříděno. Algoritmus rychlého řazení obsahuje následující kroky.
- První prvek nebo libovolný náhodný prvek vybraný jako klíč předpokládá klíč = A (1).
- Ukazatel „low“ je umístěn na druhém a ukazatel „up“ je umístěn na posledním prvku pole, tj. Low = 2 a up = n;
- Důsledně zvyšujte ukazatel „nízký“ o jednu pozici, dokud (tlačítko A [nízká]>).
- Neustále snižujte ukazatel „nahoru“ o jednu pozici do (A [nahoru] <= klíč).
- Pokud je vyšší než nízká výměna A [nízká] s A [nahoru].
- Opakujte krok 3, 4 a 5, dokud podmínka v kroku 5 nevypadne (tj. Nahoru <= nízká) a poté přepněte A [nahoru] s klíčem.
- Pokud jsou prvky vlevo od klíče menší než klíč a prvky vpravo od klíče jsou větší než klíč, pole je rozděleno na dvě dílčí pole.
- Výše uvedený postup je opakovaně aplikován na podskupiny, dokud není celé pole tříděno.


Výhody a nevýhody
Má dobré průměrné chování případu. Doba běhu složitosti rychlého řazení je dobrá, že je rychlejší než algoritmy, jako je třídění bublin, třídění vkládání a výběr. Je však složitá a velmi rekurzivní, proto není vhodná pro velká pole.
Definice slučování řazení
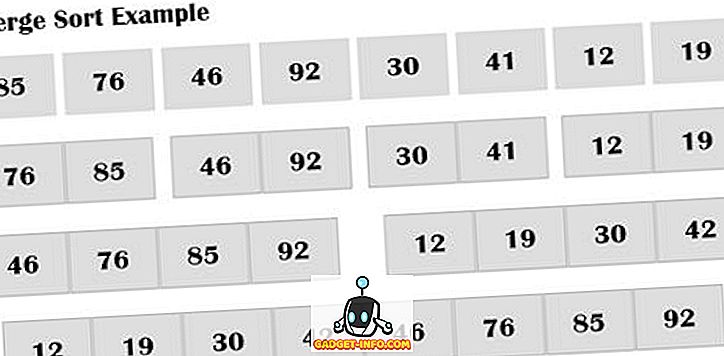
Merge sort je externí algoritmus, který je také založen na strategii dělení a dobývání. Prvky jsou znovu a znovu rozděleny na dílčí pole (n / 2), dokud nezůstane pouze jeden prvek, což významně snižuje dobu třídění. Používá přídavné úložiště pro ukládání pomocného pole. Třídění sloučení používá tři pole, kde dvě se používají pro uložení každé poloviny a třetí se používá k uložení konečného tříděného seznamu. Každé pole se potom rekurzivně třídí. Subarrays jsou konečně sloučeny tak, aby byla velikost n elementu pole. Seznam je vždy rozdělen na polovinu (n / 2) odlišnou od rychlého řazení.
Nechť A je pole n počtu prvků, které mají být tříděny A [1], A [2], ………, A [n]. Druh sloučení následuje zadané kroky.
- Rozdělte pole A na přibližně n / 2 seřazené dílčí pole o 2, což znamená, že prvky v (A [1], A [2]), (A [3], A [4]), (A [ k], A [k + 1]), (A [n-1], A [n]) dílčí pole musí být v seřazeném pořadí.
- Zkombinujte každý pár párů, abyste získali seznam tříděných dílčích řetězců o velikosti 4; prvky v subarrays jsou také v uspořádaném pořadí, (A [1], A [2], A [3], A [4]), ……, (A [k-1], A [k], A [k + 1], A [k + 2]), ……., (A [n-3], A [n-2], A [n-1], A [n]).
- Krok 2 se provádí opakovaně, dokud neexistuje pouze jedno seřazené pole velikosti n.

Výhody a nevýhody
Algoritmus slučovacího třídění se provádí přesně stejným a přesným způsobem bez ohledu na počet prvků zahrnutých do třídění. Funguje dobře i s velkým souborem dat. Využívá však větší část paměti.
Klíčové rozdíly mezi rychlým tříděním a tříděním
- V typu sloučení musí být pole rozděleno na dvě poloviny (tj. N / 2). Proti tomu, v rychlém druhu, není nutná nutnost rozdělit seznam na stejné prvky.
- Nejhorší případ složitosti rychlého řazení je O (n2), protože v nejhorším stavu trvá mnohem více porovnání. Naopak, slučovací řazení má stejný nejhorší případ a průměrné případové složitosti, tj. O (n log n).
- Sloučení může dobře fungovat na libovolném typu datových sad, ať už je velké nebo malé. Naopak, rychlé řazení nemůže fungovat s velkými množinami dat.
- Rychlé třídění je rychlejší než slučování v některých případech, například u malých souborů dat.
- Sloučení řazení vyžaduje další paměťové místo pro uložení pomocných polí. Na druhou stranu, rychlé třídění nevyžaduje mnoho místa pro další úložiště.
- Sloučení je efektivnější než rychlé řazení.
- Rychlé třídění je interní metoda třídění, kde se data, která mají být tříděna, upravují současně v hlavní paměti. Naopak, slučovací druh je externí metoda třídění, ve které data, která mají být tříděna, nemohou být současně uložena v paměti a některé musí být uchovávány v pomocné paměti.
Závěr
Rychlé řazení je rychlejší, ale v některých situacích je neefektivní a také provádí spoustu porovnání ve srovnání s druhem slučování. Ačkoli řazení sloučení vyžaduje méně srovnání, potřebuje pro ukládání přídavného pole další paměťový prostor 0 (n), zatímco rychlé třídění potřebuje prostor O (log n).



![zábava - Stav hudebního průmyslu [PICS]](https://gadget-info.com/img/entertainment/673/state-music-industry.png)
